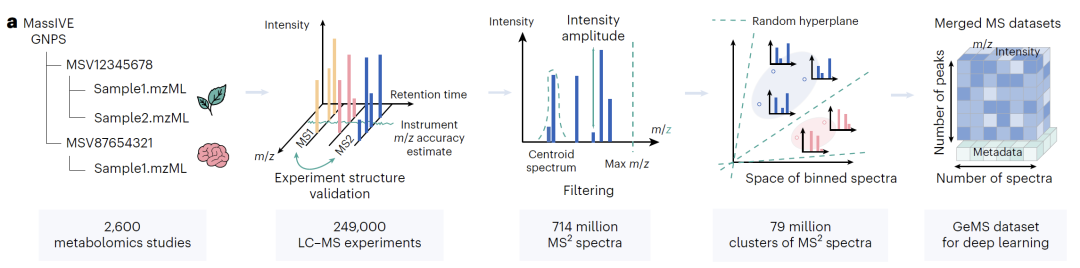
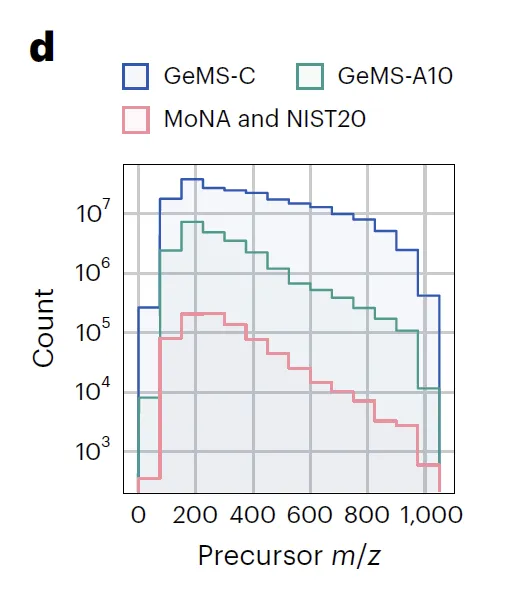
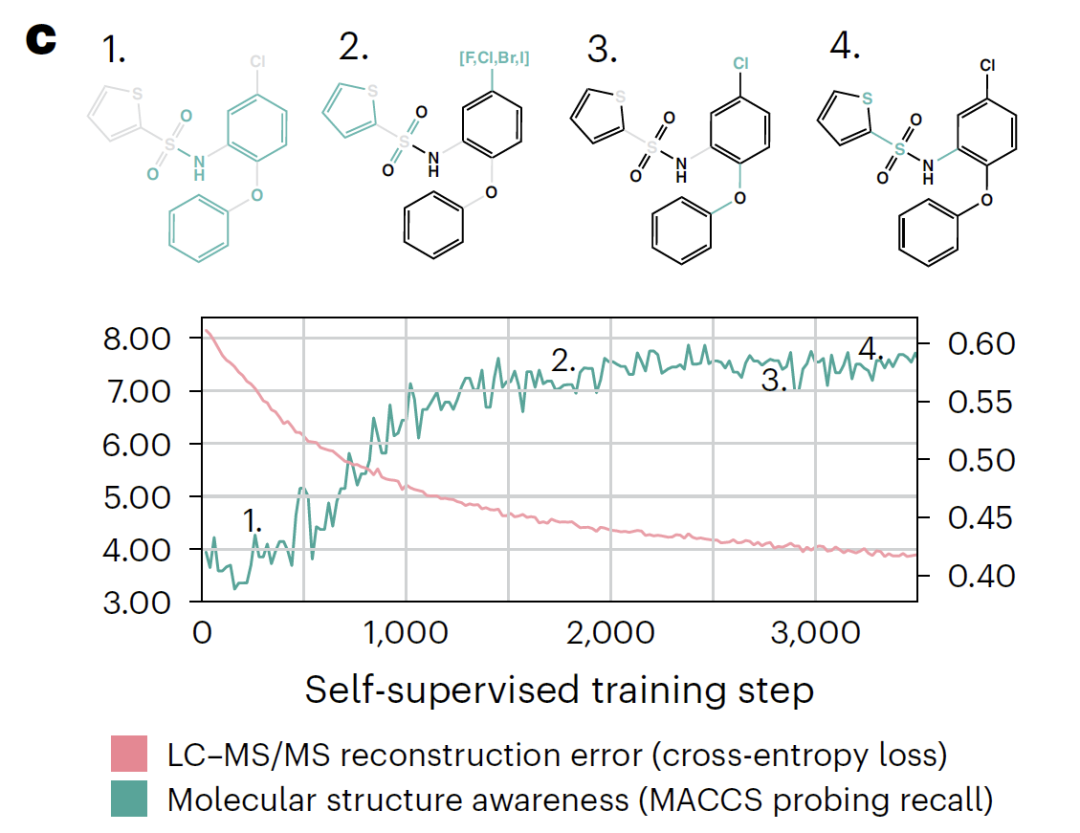
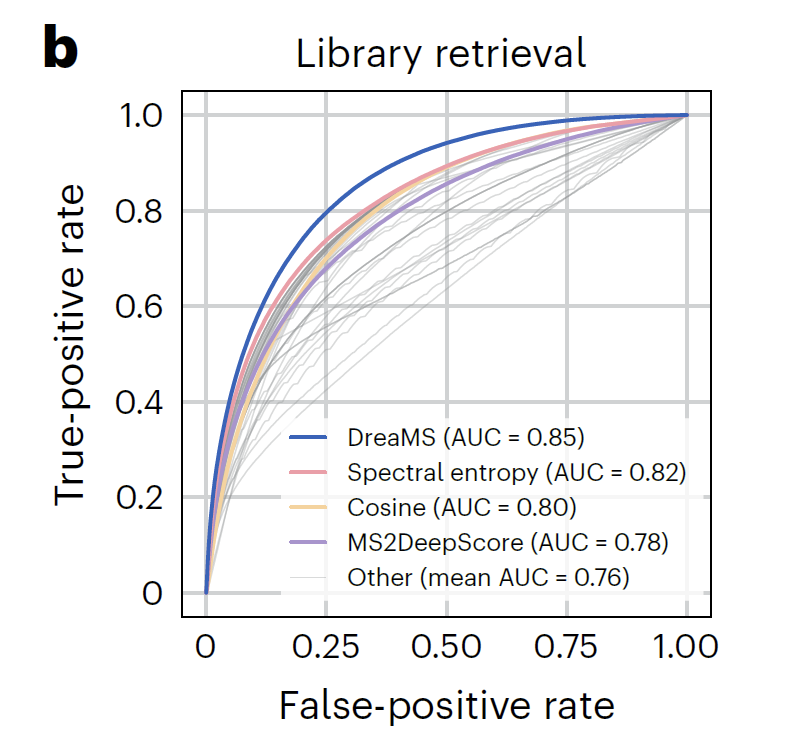
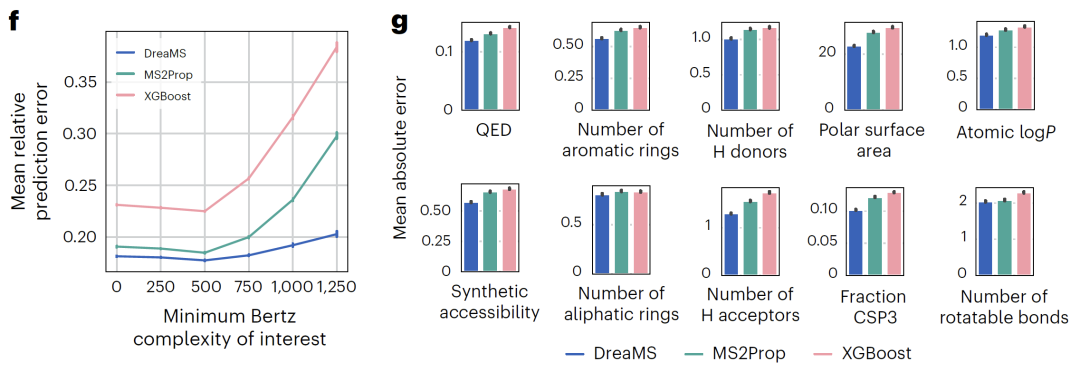
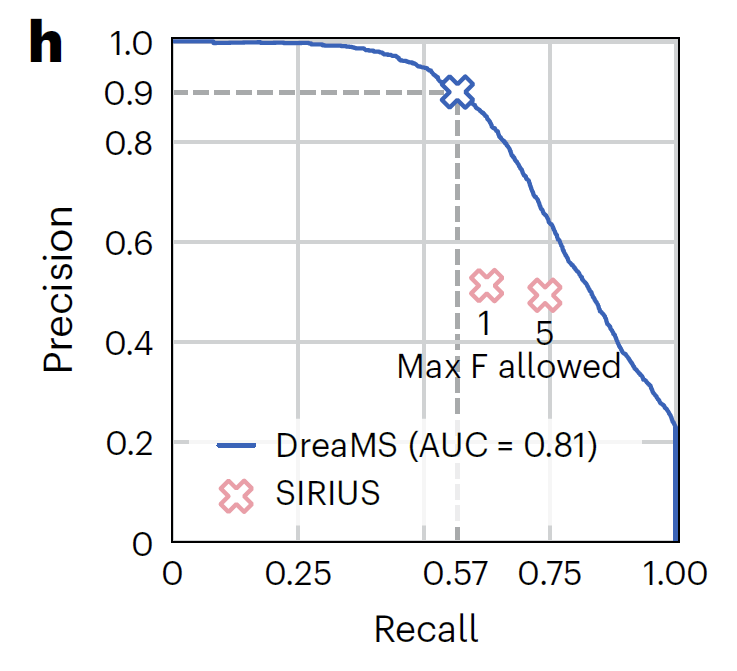
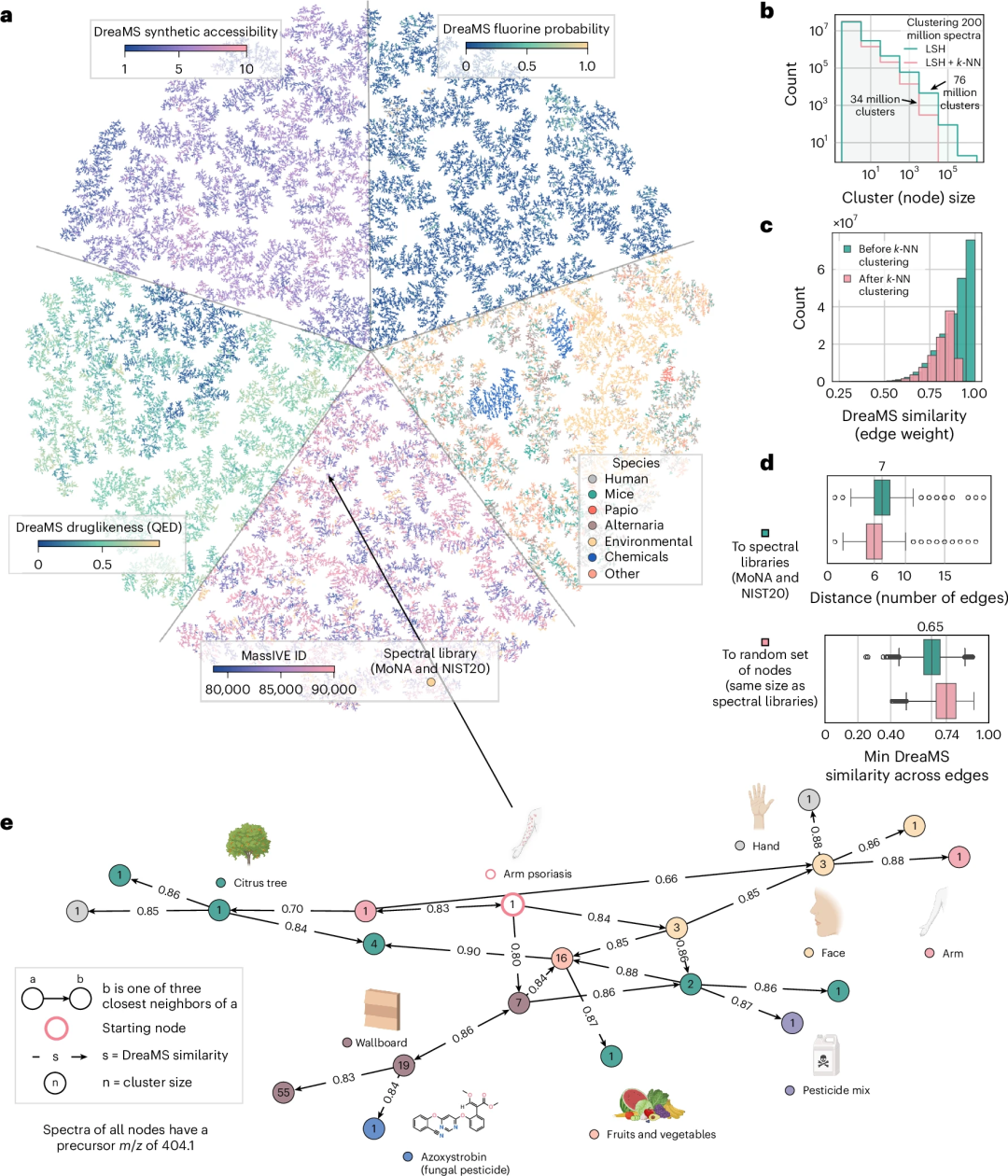
研究表明,经过微调的 DreaMS 在多种质谱注释任务中表现卓越,包括预测光谱相似性、分子指纹、化学性质以及氟元素的存在等,均超越了传统算法和近期开发的机器学习模型。更令人瞩目的是,DreaMS 图谱已整合 2.01 亿条谱图,构建起涵盖细菌、植物、人体代谢物的超级分子网络,为化学界打造了一部能够实时更新的「分子百科全书」,为相关领域的研究与应用提供了极具价值的资源。
相关研究成果以「Self-supervised learning of molecular representations from millions of tandem mass spectra using DreaMS」为题,已发表于国际权威期刊 Nature Biotechnology。
在企业创新实践中,美国公司安捷伦推出了 Pro iQ 系列等新一代液质检测系统,具有卓越的性能和灵敏度,是复杂生物分子监测和杂质检测的理想之选。其质量范围扩大至 m/z 2–3000,并通过安捷伦喷射流离子源(AJS)技术提高了灵敏度,支持小分子和大分子的常规和痕量检测,为食品安全监管提供了颠覆性技术手段。中国企业凯莱谱科技依托液相色谱串联质谱技术,自主研发的 20 余款临床质谱试剂盒产品,覆盖 300 余个检测项目,其中血液和尿液中儿茶酚胺代谢物的检测试剂已写入中华医学会内分泌学会专家共识,成为临床金标准。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡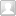 发表于 2025-6-6 14:36
发表于 2025-6-6 14:36



 提升卡
提升卡


