金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
大模型推理过程,可以分为两个阶段,预填充阶段(prefill stage)和解码阶段(decode stage)。预填充阶段是计算密集型,解码阶段为内存密集型,两个阶段分别具有不同的推理特性。如果把两个阶段放在同一个计算设备上,会导致两阶段优化目标SLOs冲突,而且耦合了两个阶段的部署策略。将两个阶段分别部署到不同的设备上,使用PD分离架构推理,各自优化,势在必行!
对应视频:
【大模型推理-PD分离架构,势在必行!】
1,推理指标定义
- 服务级目标 service level objectives (SLO):为提供一个满意的用户体验,大模型推理服务需要满足的一系列指标,一般包括首字延迟 (TTFT),平均出词时间(TPOT),端到端延迟(E2E),指数移动平均(EMA)。
- 首字延迟 time to first token latency (TTFT):模型服务产生首字的延迟时间。
- 平均出词时间 time per output token (TPOT):模型服务生成单字的平均时间,生成token的总时间处于总token数量。
- 令牌间时间 token between token:模型生成文本时,相邻两个token生成之间的时间间隔,反应模型生成过程中的实时性和稳定性。其计算方式是通过统计分析所有相邻token的时间间隔计算平均值,中位数,标准差等。
- 端到端延迟时间 end-to-end latency (E2E):从用户发起请求到最终收到完整响应所经历的总时间。它不仅仅是模型完成推理的时间还包含请求处理全链路中所有环节的耗时总和。
- 指数移动平均 exponential moving average (EMA):一种加权平均方法,对最近的延迟数据赋予更高权重,历史数据权重按指数衰减
- 吞吐量 throughput:大模型每秒钟完成请求的数量。
- goodput和吞吐类似,一秒钟完成的请求个数,但是请求完成指标必须满足SLOS要求。吞吐量统计了一秒钟完成请求的个数,但是忽略了SOLs的性能要求。

2,推理过程特性分析
大模型预填充阶段主要用于处理prompt生成KV缓存,解码阶段根据缓存结果,自回归的生成下一个token。

2.1,预填充阶段 Prefill Stage
作用:
- 初始化KV Cache:处理输入的初始序列(如用户提示词或上下文),计算并缓存所有输入token的Key和Value向量,为后续解码阶段做准备。
- 一次性计算:避免在解码阶段重复计算历史token的中间结果。
关键特点:
- 计算密集型:完整运行模型的前向传播,计算所有输入token的注意力。复杂度与输入长度平方相关 o(n^2)。
- 并行化处理:输入的所有token可并行计算,充分利用GPU等硬件加速。
2.2,解码阶段 Decode Stage
作用:
- 自回归生成:基于Prefill阶段缓存的KV向量,逐个生成新token。
- 增量更新KV cache:每次生成新token时,仅计算当前token的KV向量并追加到缓存中,复用历史KV向量。
关键特点:
- 内存密集型:依赖KV cache读取历史数据,内存带宽可能成为瓶颈。
- 串行化生成:每次只能生成一个token,严格的自回归过程。
- 计算最新token的注意力,复杂度与序列长度线性相关,O(n)。
2.3 两阶段协同与优化
在流式输出场景,Prefill 阶段仅在首次处理用户输入时执行,后续交互直接进入Decode 阶段。
| 特性 | Prefill Stage | Decode Stage | | 输入 | 初始提示词 Prompt | 前一步生成的token | | 计算复杂度 | o(n^2) n为输入prompt的长度 | o(1) per token 总为 o(n) | | 并行性 | 完全并行 | 严格串行 | | 资源消耗 | GPU计算单元 FLOPs | 内存和通信带宽 | | 输出 | 除首字外,无新token生成 | 逐个生成token | | 性能瓶颈 | 受限于计算能力 FLOPs | 受限于内存带宽,即KV cache 的读写速度 | | 工程优化 | 适用Flash Attention 等技术加速长序列处理 | 通过Page Attention、内存压缩等技术降低KV cache内存占用 |
3,为什么要PD分离
3.2 PD共置的问题
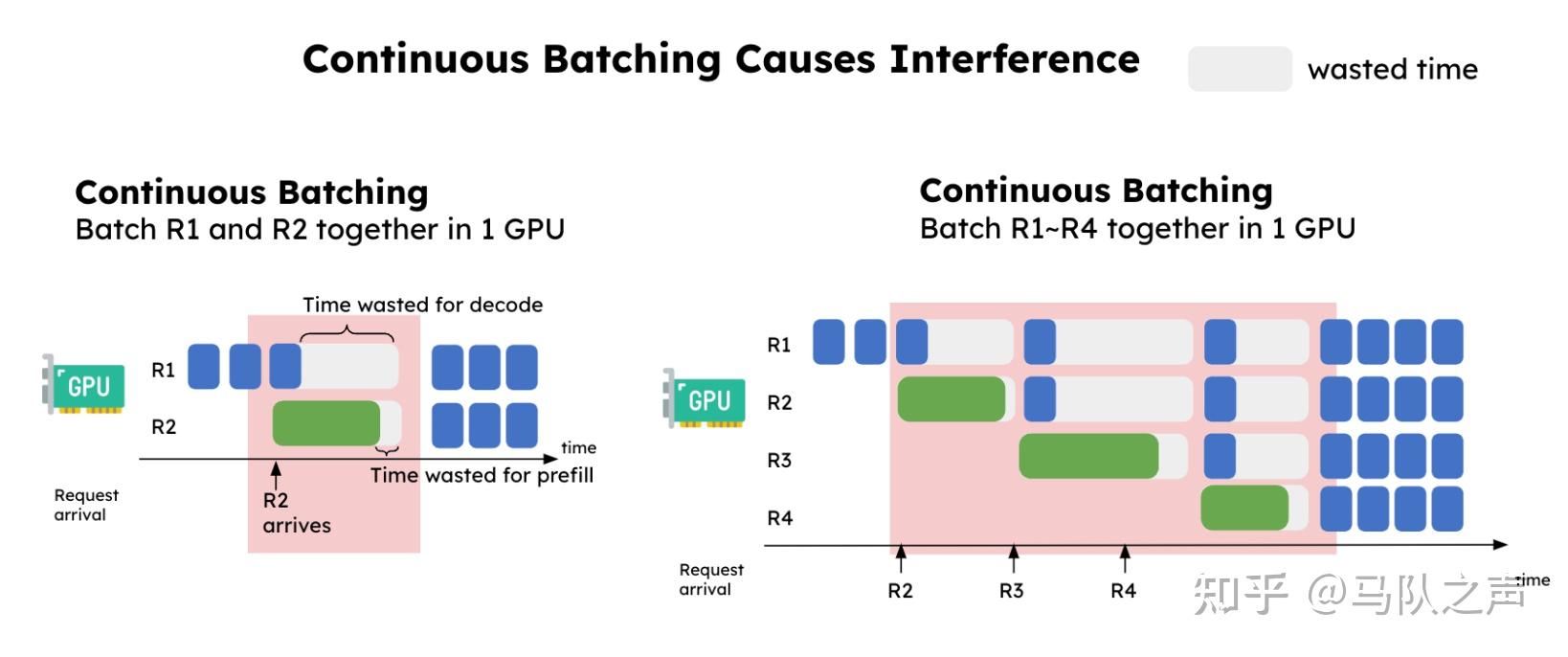
大模型推理先经过Prefill生成KV cache和首字后,传给Decode阶段,进行自回归解码生成新token。即单batch推理,prefill和decode阶段串行,互不干扰,但吞吐不高。看起来完美, 但。。。
为了满足高吞吐量,必须进行批量推理,如 continuous batch,同时将多个请求输入到LLM中,batch中一条请求结束,自动的将其剔除batch,并添加新的请求到batch中,从而满足高并发的要求。
但是,将预填充与解码阶段共置 allocate(即在同一设备上),并使用持续批处理,会导致两个主要问题:
- 批量推理时会相互干扰,导致计算资源浪费,TBT延迟时间有突刺,用户感受到明显卡顿。 假如batch大小为2,此时一个请求A,正进行decode 阶段,另外一个新请求B刚加入batch,进行prefil阶段。B请求的prefill处理时长大于A请求的decode时长,此时A请求出现明显的出字卡顿问题。同时因为AB请求对资源的争用,B请求的首字时长也会延长。
- 会耦合两者的资源分配与并行策略 预填充阶段为计算密集型,推理时适合使用模型并行策略。解码阶段是内存密集型适合使用数据和流水线并行。如果预填充和解码同时配置在一个计算设备上,并行策略不能单独配置。
DistServe 的实验结果显示,Prefill 阶段:在请求率较小时,更适合张量并行(TP)。在请求率较大时,更适合流水线并行(PP)。Decode 阶段:GPU 数量增加时,PP 可显著提高吞吐量(因为其处理方式是流水线化的)。TP 则可降低延迟(减少单个请求的处理时间)。
3.3 PD 分离方案技术
DistServe 尝试优化了资源分配与并行策略达到更好的 GPU goodput,其整体的方案如图。
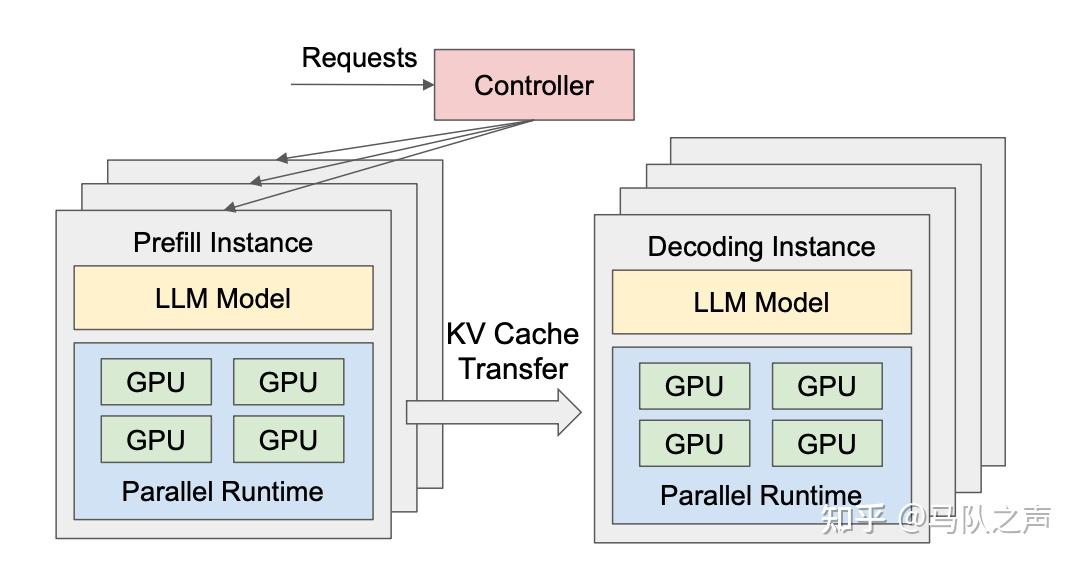
PD 分离式架构:
- 大模型的预填充阶段,部署在 Prefill Instance 节点上,专注于 Prefill 阶段的计算,得到KV 缓存。
- 大模型的推理阶段,部署在Decode Instance 专注于 Decode 阶段自回归的生成任务。
推理流程是,当 Prefill Instance 完成 KV cache 的计算后,会将其传输给 Decode Instance,后者接续生成结果。PD分离架构的优势是,两个阶段部署在不同服务器,可以各自优化,进而使得总的吞吐和计算设备利用率最大化。
PD分离架构一个核心点是,KV cache 的计算和传递,其影响着整个架构的调度设计。
Mooncake 进一步发展了PD分离架构,提出了一种以键值缓存(KVCache)为中心的分离式 LLM 服务架构。通过优化 KVCache 的管理和传输,Mooncake 在满足服务水平目标(SLO)的前提下,实现了高达 525%的吞吐量提升。在实际工作负载下,Mooncake 使得 Kimi 系统的请求处理能力提高了 75%。
4,总结
本文,首先对齐大模型推理指标,然后分析大模型预填充和解码阶段特性,并以此为基础,关注到持续批量通过阶段隔离和抢占机制处理带来高吞吐,缩短TTFT同时,也显著增加TBT的尾部延迟,进而影响E2E延迟。最后介绍PD分离方案的技术路线。
参考:
[1] Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Aashaka Shah, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. arXiv preprint arXiv:2311.18677, 2023.
[2] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. arXiv preprint arXiv:2401.09670, 2024. blog: https://hao-ai-lab.github.io/blogs/distserve/
[3] Ruoyu Qin, Zheming Li, Weiran He, Mingxing Zhang, Yongwei Wu, Weimin Zheng, Xinran Xu. Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving. arXiv:2407.00079
原文地址:https://zhuanlan.zhihu.com/p/1897270081664300462 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-5-30 20:51
发表于 2025-5-30 20:51
 提升卡
提升卡


