DRUGAI
今天为大家介绍的是来自瑞士的博特纳免疫工程研究所Sai T. Reddy团队的一篇论文。免疫系统中最重要的防御武器是免疫受体,其中包括B细胞受体(BCR)、它们分泌的抗体,以及T细胞受体(TCR)。这些免疫受体就像是免疫系统的“智能雷达”,能够精确识别和对抗入侵者。它们最神奇的特点是拥有一个高度灵活的识别区域,可以通过改变自身结构来识别数不胜数的不同入侵物质(抗原)。虽然AI领域的明星工具AlphaFold(一个能够预测蛋白质结构的人工智能系统)在蛋白质结构预测方面取得了突破性进展,但在预测免疫受体方面仍面临两大挑战:一是高质量的免疫受体结构数据太少,二是免疫受体与入侵物质之间的相互作用机制过于复杂。在这篇综述中,作者重点介绍了两个关键领域的最新进展:一是基于免疫受体序列信息的数据生成技术,二是基于其结构信息的数据生成方法。这些进展对于开发能够预测免疫受体识别特性的机器学习模型至关重要。同时,作者也探讨了当前面临的技术瓶颈,以及未来如何更好地利用海量多维度数据来预测和设计具有特定识别功能的抗体和T细胞受体。
抗体与T细胞受体的模型开发难度差异显著:抗体因高亲和力与可溶性表达更易表征,而TCR靶向MHC分子呈递的短肽,表位空间更为受限。尽管两者抗原景观差异使数据需求难以精确估算,但保守预测需将数据规模扩展 至少一个数量级(甚至多个数量级),方可覆盖更广泛的抗原-表位组合。要实现免疫受体特异性预测的突破,必须强化湿实验(生物实验室实体实验)与计算研究的协作。双方需深入理解彼此领域的数据生成瓶颈与模型开发需求,从而优化实验设计、提升数据质量,最终训练出能精准预测并设计免疫受体特异性的强泛化机器学习模型。
编译 | 于洲
审稿 | 王梓旭
参考资料
Mason D M, Reddy S T. Predicting adaptive immune receptor specificities by machine learning is a data generation problem[J]. Cell Systems, 2024, 15(12): 1190-1197.

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡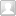 发表于 2025-3-3 08:58
发表于 2025-3-3 08:58



 提升卡
提升卡


