言归正传,摘录方佳瑞学长的观点,PD 分离有几个层面:
Level -1:PD 在单卡上融合,这和 PD 分离南辕北辙。
Level 0:PD 分开计算,但是放在一张卡上调度。这是推理框架的 default 实现,目前的 SGLang v 0.3 也采用了这种方案。
Level 1:分离 P D 在同构设备的同构网络中。比如 P D 都在同一个 A800 节点内,不需要在集群层面进行改造。
Level 2:分离 P D 到同构设备的不同网络中。譬如 P D 分别占据一个完整的 A800 节点,不需要显著改造集群,但是需要建立集群间的高效通讯,譬如 RDMA。
Level 3:彻底分离 P D 到异构设备的异构网络中。譬如 P 占据一个完整的 MI 300 集群,而 D 占据另一个完整的 H20 集群,需要对集群进行显著的改造,并且需要节点间的高效通讯。
两天前我做了个简单的讨论:
这里进一步扩展下结论:
异构设备未必能够降低成本:虽然理论上可以采用更便宜的卡,但是 networking 成本不可忽略,而在一个大规模 data center 中部署多种机型也有不可忽略的 fragmentation 代价。
论述了这么多,接着参考业界已有的成熟方案看看 P / D 分离进行到底后的效果。值得再次强调的是,P / D 分离进行到底对于 kimi chat 这样的应用应该是非常 adorable 的,毕竟 kimi 的长文本能力是其突出卖点。不过就我个人而言,我对长文本的需求基本来自 LLM 读文档,而今天我发觉没有什么成熟的应用不具有这个功能。
Introduction
Mooncake 相比于开源框架而言,能利用的资源更多,但是需要考虑的限制也更复杂。就我所知,当前的 open source serving engine 很难考虑到如何 fully utilize DRAM SSD RDMA 这样的硬件条件。然而,open source engine 可能也不太用考虑 SLO(service level objective 也即用户优先等级)的问题?
Mooncake 将计算操作和硬件资源都进行了彻底的解构。对于后者而言,所有的硬件都被解耦而后重新建立了对应的资源池。每种资源池(比如 CPU 池、DRAM 池、SSD 池)各自有独立的优化目标,以期望整体达到最大优化。
P D 彻底分节点进行导致设计者必须考虑 KV cache 在 P D 节点之间传输的问题。如下图所示,KV Cache 需要考虑 P D 之间所有的传输需求。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡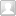 发表于 2024-12-26 08:16
发表于 2024-12-26 08:16



 提升卡
提升卡


